
When Meta introduced the Llama 4 series in April 2025, it was a major platform advancement for artificial intelligence. Llama 4 builds on previous models to introduce new advanced architecture and capabilities that will transform AI applications across numerous fields.
Meta’s newest venture under the Llama 4 banner focuses on the advanced development of state-of-the-art large language models (LLMs). This series presents a mixture-of-experts (MoE) architecture that ensures higher efficiency and enhanced performance. The first versions of Llama 4 introduce two primary models: Llama 4 Scout and Llama 4 Maverick. The development of Llama 4 Behemoth continues as the third model in the series. Proximate Solutions brings in all the latest insight on Llama 4 through this comprehensive blog. Read this blog thoroughly and find out what Meta’s release of the Llama 4 series is all about.
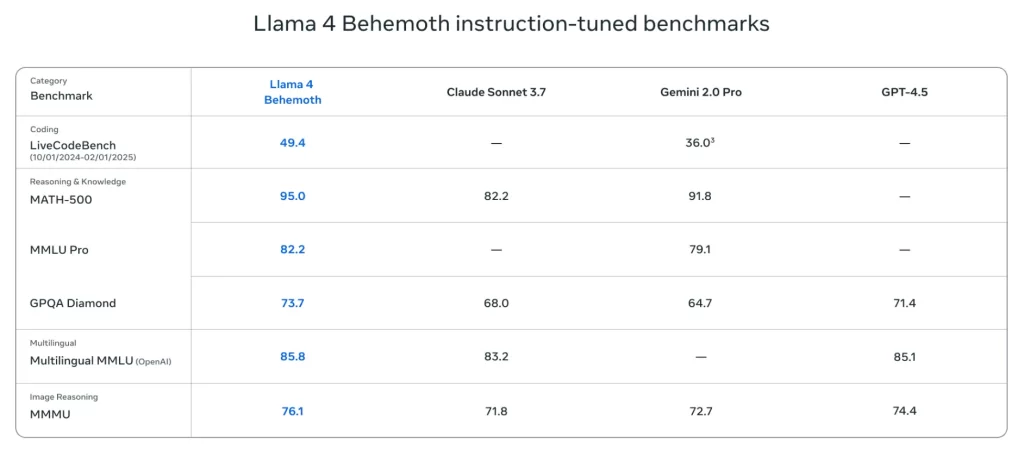
Meta developed Llama 4 Scout to respond to the business requirement for large yet optimized AI models. Scout operates via a mixture-of-experts (MoE) architectural design that selects 17 billion active parameters from 109 billion total parameters spread across 16 expert networks to maintain high performance and decrease operational expenses. The model runs successfully on a standalone NVIDIA H100 GPU and hence provides state-of-the-art AI capabilities to small enterprises and individual researchers and developers.
The 10-million-token context window in Scout stands out as its defining feature. It proves excellent for lengthy documents, multi-turn dialogue, coding assignments, and extensive research. Large and complex data inputs serve as no obstacle for this model since it operates efficiently with extended information assignments and provides capabilities for applications such as code assistant systems and legal document evaluation tools.
Scout’s compact system matches its benchmark performance with existing standards. The system effectively constructs AI agents, chatbots, and customer support systems and tools that need deep contextual memory capabilities. The Llama 4 Scout delivers impressive processing power, energy efficiency, and cost-effective accessibility, demonstrating that top-tier AI capabilities remain approachable for budget-constrained teams.
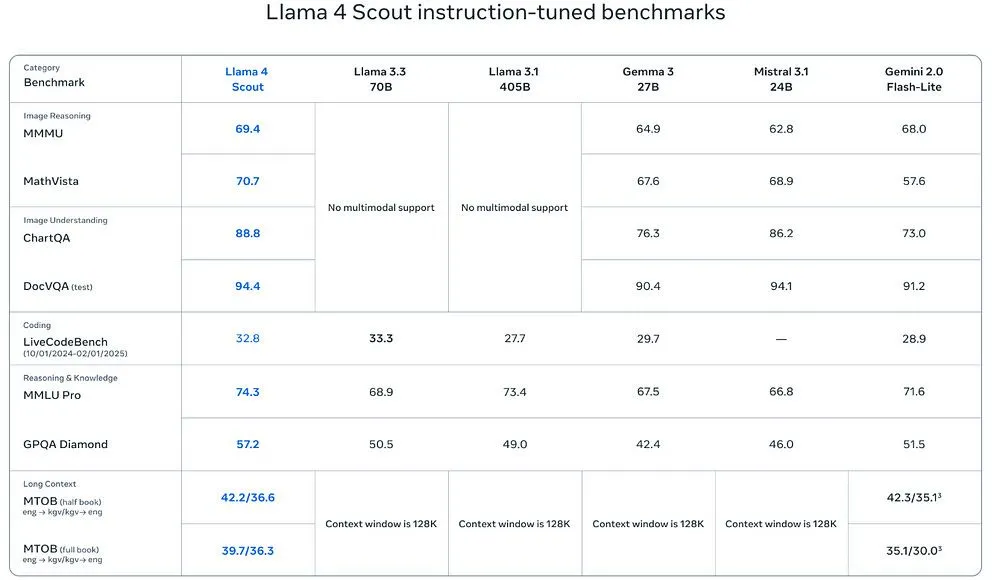
Llama 4 Maverick stands as Meta’s most advanced model within the Llama 4 lineup because it uses 128 experts while accomplishing a total of 400 billion parameters in its Mixture-of-Experts (MoE) architecture. The efficient design of Maverick reduces the number of active parameters to 17 billion even though it includes 400 billion parameters. The model operates with excellent performance standards without requiring unreasonable computing demands.
The strategic design of Maverick provides operational effectiveness to both enterprise users and advanced AI development teams that seek performance while avoiding unnecessary spending. Maverick presents benchmarks that challenge top-class models GPT-4o and Gemini 2.0 Flash, particularly in coding tasks, reasoning capabilities, and multi-turn dialogue performance.
This ability to produce sophisticated content throughout numerous tasks establishes the model as a leading force within the large language model sector. Llama 4 Maverick offers a unique blend of scalability, intelligence, and computational efficiency, which proves that more parameters don’t have to mean more friction.
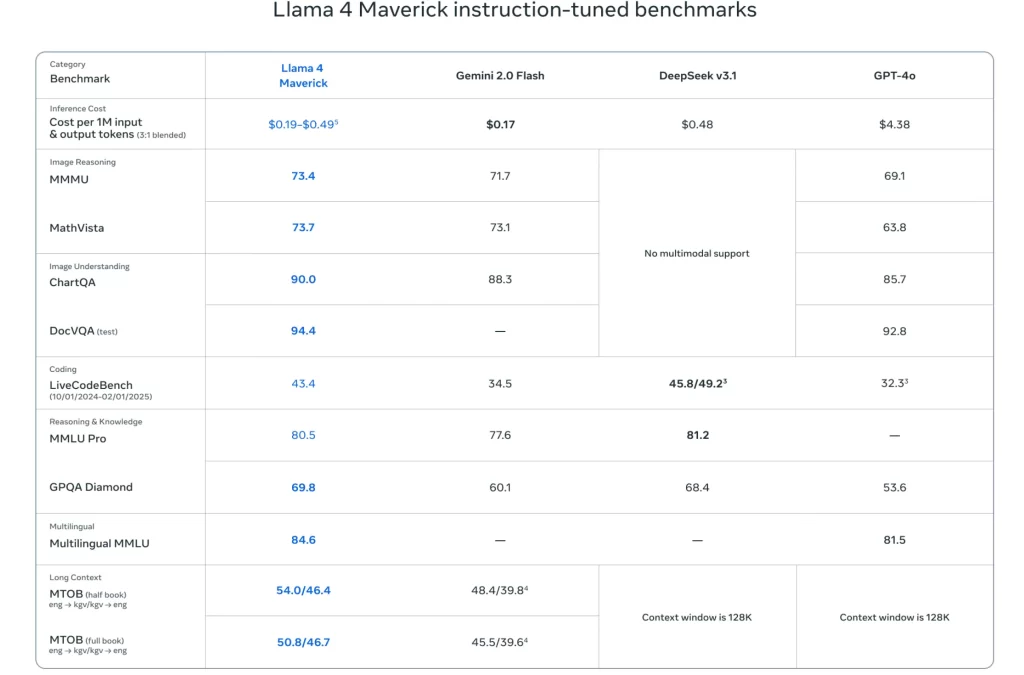
The Llama 4 Behemoth is the biggest and most advanced language model within Meta’s product line. Meta expects Llama 4 Behemoth to reach 288 billion active parameters while approaching 2 trillion parameters, thus creating a new benchmark in AI capability. The development work on Behemoth demonstrates that this model will surpass GPT-4.5 and Claude Sonnet 3.7 and show superiority in STEM benchmarks and demanding reasoning tasks.
The model serves advanced organizations conducting research labs, enterprise applications and performs complex AI operations with deep understanding requirements. Large-scale, high-performance AI systems will find their future representation in Behemoth.
Llama 4 implements a Mixture-of-Experts (MoE) architecture, which delivers both high efficiency and intelligent performance. MoE activates only two expert networks from its multiple network pool instead of activating the whole program for every task. The selected network activation pattern decreases operational costs and delivers high system performance. Through the application of this design to an extensive model, the solution becomes accessible to more users despite its ability to scale to billions of parameters.
Llama 4 can efficiently deliver complex queries, processing automated coding services and nuanced reasoning operations, leading to its status as a strategic tool for practical implementations that require both vast capacities and fast response times.
Llama 4 models were developed with native multimodal functionality that enables them to process both text and image inputs and respond with text-based outputs. These artificial intelligence models work with various real-world applications from visual analysis to cross-platform communication. These model solutions support twelve primary languages and are multilingual which achieves wider market adaptability for international non-English markets and facilitates development by non-English teams.
The Llama 4 system receives deep integration from Meta within WhatsApp, Messenger and Instagram Direct thus providing enhanced AI capabilities to every one of its billion users. Users can easily connect to level-up AI capabilities through their regular messaging platforms. Users who want to use Llama 4 models can find them at the Meta AI website where they can test and experiment with the versatile capabilities of this AI platform.

Llama 4 surpassing other models when tested on prominent benchmark assessments particularly when performing reasoning operations and coding initiatives. The reported findings about Llama 4 have generated discussions among experts. The testing phase utilized an optimized version of the Maverick model which was specifically adjusted for conversational capabilities according to published reports but some researchers have doubts about evaluation accuracy and fairness. AI benchmarking transparency remains a critical issue because the recent controversy exposes difficulties with conducting fair model comparison experiments.
Llama 4 represents an essential advancement toward Meta’s objective of achieving leadership position in artificial intelligence. Meta invests $65 billion to develop AI infrastructure and research between 2025. This indicates the company’s global standard-setting ambitions for the Llama model family.
Future AI development will lead to enhanced systems which use Llama 4 Behemoth as their foundation. The company competes strongly against OpenAI and Google through these developments to define AI development routes for both personal use applications and business-oriented implementations that span various sectors.
Llama 4 verifies Meta’s expert level in developing effective large language models with multi-modal and scalable functionalities. The multilingual content capabilities, enhanced performance and real-time functionality throughout Meta platforms make this model actively change how people communicate and work and create new content. The innovation value of Llama 4 maintains its importance even through the ongoing disputes regarding benchmarking strategies.
The future direction of Llama 4 developments at Meta will receive focused attention both from the AI community. The global world to understand its transformative impact on operational business processes and digital experience.
When Meta introduced the Llama 4 series in April 2025, it was a major platform advancement for artificial intelligence. Llama 4 builds on previous models to introduce new advanced architecture and capabilities that will transform AI applications across numerous fields.
Meta’s newest venture under the Llama 4 banner focuses on the advanced development of state-of-the-art large language models (LLMs). This series presents a mixture-of-experts (MoE) architecture that ensures higher efficiency and enhanced performance. The first versions of Llama 4 introduce two primary models: Llama 4 Scout and Llama 4 Maverick. The development of Llama 4 Behemoth continues as the third model in the series. Proximate Solutions brings in all the latest insight on Llama 4 through this comprehensive blog. Read this blog thoroughly and find out what Meta’s release of the Llama 4 series is all about.
Meta developed Llama 4 Scout to respond to the business requirement for large yet optimized AI models. Scout operates via a mixture-of-experts (MoE) architectural design that selects 17 billion active parameters from 109 billion total parameters spread across 16 expert networks to maintain high performance and decrease operational expenses. The model runs successfully on a standalone NVIDIA H100 GPU and hence provides state-of-the-art AI capabilities to small enterprises and individual researchers and developers.
The 10-million-token context window in Scout stands out as its defining feature. It proves excellent for lengthy documents, multi-turn dialogue, coding assignments, and extensive research. Large and complex data inputs serve as no obstacle for this model since it operates efficiently with extended information assignments and provides capabilities for applications such as code assistant systems and legal document evaluation tools.
Scout’s compact system matches its benchmark performance with existing standards. The system effectively constructs AI agents, chatbots, and customer support systems and tools that need deep contextual memory capabilities. The Llama 4 Scout delivers impressive processing power, energy efficiency, and cost-effective accessibility, demonstrating that top-tier AI capabilities remain approachable for budget-constrained teams.
Llama 4 Maverick stands as Meta’s most advanced model within the Llama 4 lineup because it uses 128 experts while accomplishing a total of 400 billion parameters in its Mixture-of-Experts (MoE) architecture. The efficient design of Maverick reduces the number of active parameters to 17 billion even though it includes 400 billion parameters. The model operates with excellent performance standards without requiring unreasonable computing demands.
The strategic design of Maverick provides operational effectiveness to both enterprise users and advanced AI development teams that seek performance while avoiding unnecessary spending. Maverick presents benchmarks that challenge top-class models GPT-4o and Gemini 2.0 Flash, particularly in coding tasks, reasoning capabilities, and multi-turn dialogue performance.
This ability to produce sophisticated content throughout numerous tasks establishes the model as a leading force within the large language model sector. Llama 4 Maverick offers a unique blend of scalability, intelligence, and computational efficiency, which proves that more parameters don’t have to mean more friction.
The Llama 4 Behemoth is the biggest and most advanced language model within Meta’s product line. Meta expects Llama 4 Behemoth to reach 288 billion active parameters while approaching 2 trillion parameters, thus creating a new benchmark in AI capability. The development work on Behemoth demonstrates that this model will surpass GPT-4.5 and Claude Sonnet 3.7 and show superiority in STEM benchmarks and demanding reasoning tasks.
The model serves advanced organizations conducting research labs, enterprise applications and performs complex AI operations with deep understanding requirements. Large-scale, high-performance AI systems will find their future representation in Behemoth.
Llama 4 implements a Mixture-of-Experts (MoE) architecture, which delivers both high efficiency and intelligent performance. MoE activates only two expert networks from its multiple network pool instead of activating the whole program for every task. The selected network activation pattern decreases operational costs and delivers high system performance. Through the application of this design to an extensive model, the solution becomes accessible to more users despite its ability to scale to billions of parameters.
Llama 4 can efficiently deliver complex queries, processing automated coding services and nuanced reasoning operations, leading to its status as a strategic tool for practical implementations that require both vast capacities and fast response times.
Llama 4 models were developed with native multimodal functionality that enables them to process both text and image inputs and respond with text-based outputs. These artificial intelligence models work with various real-world applications from visual analysis to cross-platform communication. These model solutions support twelve primary languages and are multilingual which achieves wider market adaptability for international non-English markets and facilitates development by non-English teams.
The Llama 4 system receives deep integration from Meta within WhatsApp, Messenger and Instagram Direct thus providing enhanced AI capabilities to every one of its billion users. Users can easily connect to level-up AI capabilities through their regular messaging platforms. Users who want to use Llama 4 models can find them at the Meta AI website where they can test and experiment with the versatile capabilities of this AI platform.
Llama 4 surpassing other models when tested on prominent benchmark assessments particularly when performing reasoning operations and coding initiatives. The reported findings about Llama 4 have generated discussions among experts. The testing phase utilized an optimized version of the Maverick model which was specifically adjusted for conversational capabilities according to published reports but some researchers have doubts about evaluation accuracy and fairness. AI benchmarking transparency remains a critical issue because the recent controversy exposes difficulties with conducting fair model comparison experiments.
Llama 4 represents an essential advancement toward Meta’s objective of achieving leadership position in artificial intelligence. Meta invests $65 billion to develop AI infrastructure and research between 2025. This indicates the company’s global standard-setting ambitions for the Llama model family.
Future AI development will lead to enhanced systems which use Llama 4 Behemoth as their foundation. The company competes strongly against OpenAI and Google through these developments to define AI development routes for both personal use applications and business-oriented implementations that span various sectors.
Llama 4 verifies Meta’s expert level in developing effective large language models with multi-modal and scalable functionalities. The multilingual content capabilities, enhanced performance and real-time functionality throughout Meta platforms make this model actively change how people communicate and work and create new content. The innovation value of Llama 4 maintains its importance even through the ongoing disputes regarding benchmarking strategies.
The future direction of Llama 4 developments at Meta will receive focused attention both from the AI community. The global world to understand its transformative impact on operational business processes and digital experience.


